PoseVEC: Authoring Adaptive Pose-aware Effects using Visual Programming and Demonstrations
Yongqi Zhang, Cuong Nguyen, Rubaiat Habib Kazi, Lap-Fai Yu
Abstract
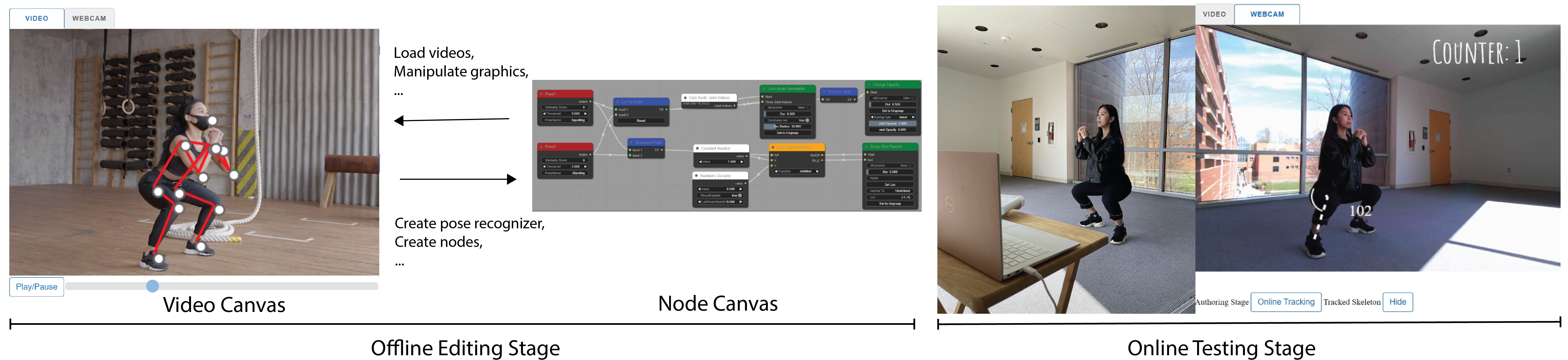
Pose-aware visual effects where graphics assets and animations are rendered reactively to the human pose have become increasingly popular, appearing on mobile devices, the web, or even headmounted displays like AR glasses. Yet, creating such effects still remains difficult for novices. In a traditional video editing workflow, a creator could utilize keyframes to create expressive but non-adaptive results which cannot be reused for other videos. Alternatively, programming-based approaches allow users to develop interactive effects, but are cumbersome for users to quickly express their creative intents. In this work, we propose a lightweight visual programming workflow for authoring adaptive and expressive pose effects. By combining a programming by demonstration paradigm with visual programming, we simplify three key tasks in the authoring process: creating pose triggers, designing animation parameters, and rendering. We evaluated our system with a qualitative user study and a replicated example study, finding that all participants can create effects efficiently.
Details
Paper
Yongqi Zhang, Cuong Nguyen, Rubaiat Habib Kazi, and Lap-Fai Yu. 2023. PoseVEC: Authoring Adaptive Pose-aware Effects using Visual Programming and Demonstrations. In The 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23), October 29–November 01, 2023, San Francisco, CA, USA.
Video
Acknowledgments
We are grateful to the anonymous reviewers for their constructive comments. This research is supported by an NSF Graduate Research Fellowship and an NSF CAREER Award (award number: 1942531). We are also thankful for Adobe Research’s support to the GMU’s DCXR Lab. We would also like to thank Ana Cardenas Gasca for providing initial feedback on our early-stage prototypes.